SQL Server 2019 での話です。
Unicode の𠮷(つちよし), 𩸽(ほっけ)や 🍺(ビール), 👨👩👧👦(家族: 父母と女の子と男の子)のような絵文字等を扱う場合、データベースがサロゲートペアや結合文字列に対応している必要があります。
SQL Server の Unicode データ型は SQL Server 2005 から対応済みで、SQL Server 2019 では新しい UTF-8 対応の照合順序も加わり、より扱いやすくなってます。
公式サイトにも説明があります。
しかし、この説明の中に補助文字に関する記述があり、SCA 照合順序なしで Unicode を扱う場合、結果として「 0 – 0xFFFF の範囲外の文字は無視されてしまう」事が示唆されています。
これが地味に影響する部分がクエリというか T-SQL の式に Unicode 文字列を使用する場合で、前述の範囲外の文字に該当する場合、その文字コードが除外された状態で式が評価される事があります。
つまり、照合順序の設定次第では「式の評価が異なるため、意図しない結果を得てしまう場合がある」という事です。
検証してみる
後述する作業は Azure Data Studio (または SSMS) から SQL Server 2019 に接続した状態で行いました。※Windows版 / Linux版 どちらも同じ結果でした。
(1) 検証用データベースの作成と照合順序の確認
検証用データベースを 2 種類用意します。
| my_test_db | 既定の照合順序のまま ※Japanese_CI_AS |
|---|---|
| my_xjis140_db | 照合順序に Japanese_XJIS_140_CI_AS を指定 |
ここでは、次の SQL 文を実行してデータベースを作成します。
CREATE DATABASE my_test_db; CREATE DATABASE my_xjis140_db COLLATE Japanese_XJIS_140_CI_AS;
照合順序の確認ではデータベースが Auto Closed のままだと情報を取得できません。
なので Azure Data Studio であれば、Manage や New Query のデータベース切替等で活性化します。
活性化が済んだら照合順序を確認します。
SELECT SERVERPROPERTY('Collation') as N'サーバの照合順序';
SELECT name, collation_name FROM sys.databases WHERE name LIKE 'my_%';

※ここで collation_name が NULL の場合、データベースが活性化してません。
(2) Unicode 文字の格納
テーブル変数に非Unicode データ型, Unicode データ型, UTF8 エンコード対応のデータ型を用意します。そこにサロゲートペアで表現される絵文字🍺と結合絵文字👨👩👧👦を格納し、それぞれの値を確認します。
DECLARE @a table (
non_unicode varchar(40),
unicode_utf16 nvarchar(40),
unicode_utf8 varchar(40) COLLATE Japanese_XJIS_140_CI_AS_UTF8
);
INSERT INTO @a VALUES (N'🍺', N'🍺', N'🍺');
INSERT INTO @a VALUES (N'👨👩👧👦', N'👨👩👧👦', N'👨👩👧👦');
SELECT * FROM @a;
SELECT
CAST(non_unicode AS varbinary),
CAST(unicode_utf16 AS varbinary),
CAST(unicode_utf8 AS varbinary)
FROM @a;
データベースに対してクエリを発行します。
※下画面の例は my_test_db で実行した結果です。
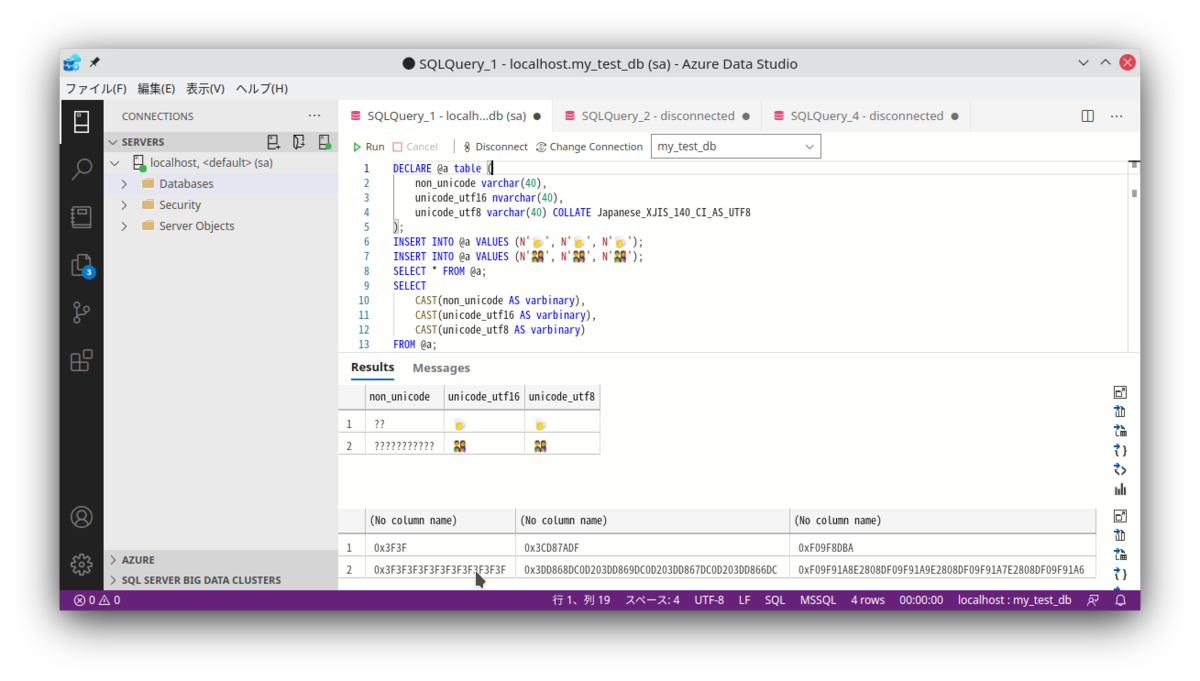
これは my_test_db, my_xjis140_db どちらで実行しても同じ結果になります。
varchar では文字が化けて ?? で埋められていますが、nvarchar と UTF8 エンコーディングを指定した varchar では、それぞれ UTF-16LE, UTF-8 で符号化された値が格納されます。
データの格納先としては、データベースの照合順序に関わらず、問題なく扱える事が確認できました。
(3) クエリの式で Unicode 文字列を使用
テーブル変数に絵文字を含む値を格納し、データを抽出してみます。
DECLARE @b table (
name_utf16 nvarchar(40),
name_utf8 varchar(40) COLLATE Japanese_XJIS_140_CI_AS_UTF8
);
INSERT INTO @b VALUES (N'超🍺ドライ', N'超🍺ドライ');
INSERT INTO @b VALUES (N'墨🍺🍺ラベル', N'墨🍺🍺ラベル');
INSERT INTO @b VALUES (N'最速🍺絞り', N'最速🍺絞り');
SELECT * FROM @b;
SELECT * FROM @b WHERE name_utf16 LIKE N'%🍺🍺%';
SELECT * FROM @b WHERE name_utf8 LIKE N'%🍺🍺%';
このクエリを実行したところ、my_test_db (照合順序: Japanese_CI_AS) と my_xjis140_db (照合順序: Japanese_XJIS_140_CI_AS) で異なる結果になりました。
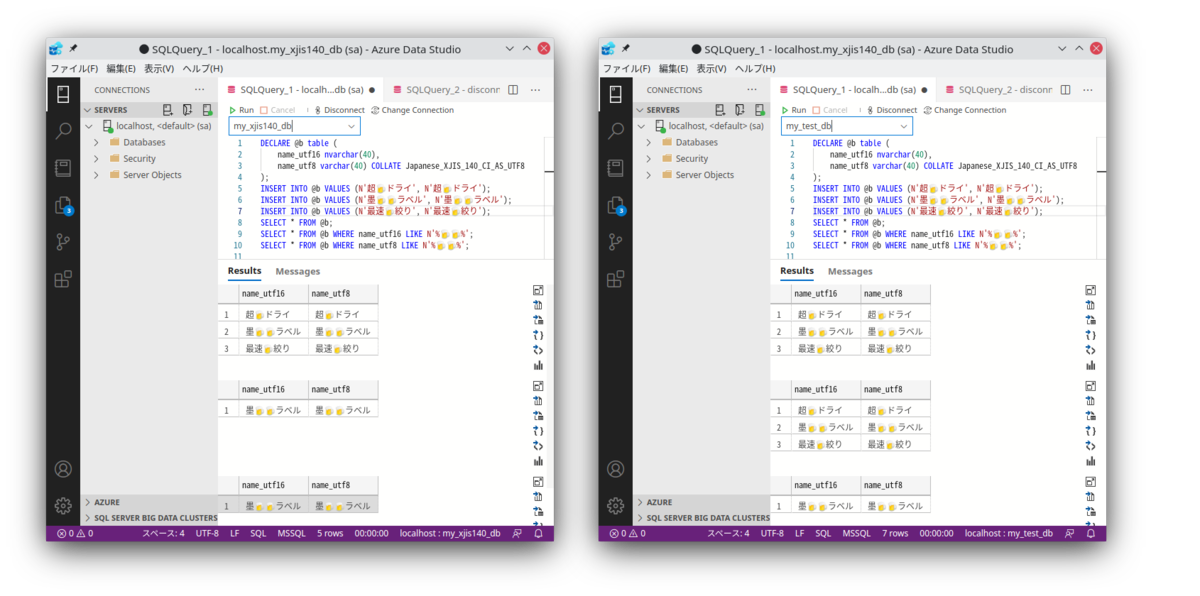
my_xjis140_db では特に問題なく、意図した結果が得られました。
しかし、my_test_db では格納したデータが期待通りに抽出できません。
照合順序 Japanese_CI_AS に補助文字のサポートが含まれないからです。
....
式の評価では、サポート対象外な文字を除いての評価になるようです。
例えば、次のクエリを my_test_db で実行すると、墨🍺ラベルが返却されます。
DECLARE @c table (
name_utf16 nvarchar(40)
);
INSERT INTO @c VALUES (N'超🍺ドライ');
INSERT INTO @c VALUES (N'中トロ🍣');
INSERT INTO @c VALUES (N'こはだ🍣');
INSERT INTO @c VALUES (N'墨🍺ラベル');
INSERT INTO @c VALUES (N'あじ🍣');
INSERT INTO @c VALUES (N'最速🍺絞り');
SELECT * FROM @c WHERE name_utf16 = N'墨🗻𩸽🍣𠮷🍺ラベル';
式の評価の際、墨🍺ラベルと墨🗻𩸽🍣𠮷🍺ラベルに含まれるサポート対象外の文字を省略すると、どちらも墨ラベルになります。
この状態で式を評価すると元の文字列が異なるのに「等しい」と評価されてしまいます。
影響は WHERE 句だけでなく、SELECT 句でも同様です。
DECLARE @d table (
name_utf16 nvarchar(40)
);
INSERT INTO @d VALUES (N'超🍺ドライ');
INSERT INTO @d VALUES (N'中トロ🍣');
INSERT INTO @d VALUES (N'こはだ🍣');
INSERT INTO @d VALUES (N'墨🍺ラベル');
INSERT INTO @d VALUES (N'あじ🍣');
INSERT INTO @d VALUES (N'最速🍺絞り');
SELECT
SUM(t.is_beer) as beer,
SUM(t.is_sushi) as sushi
FROM (
SELECT
(CASE WHEN name_utf16 LIKE N'%🍺%' THEN 1 ELSE 0 END) as is_beer,
(CASE WHEN name_utf16 LIKE N'%🍣%' THEN 1 ELSE 0 END) as is_sushi
FROM @d
) as t
特定の絵文字を含むデータ数を集計するようなクエリでは誤った集計結果になります。
一応、データベースの照合順序が Japanese_CI_AS のままでも、式の評価時に _140 系等の補助文字をサポートする照合順序を指定すれば、一時的に回避できます。
SELECT
(CASE WHEN name_utf16 COLLATE Japanese_XJIS_140_CI_AS LIKE N'%🍺%' THEN 1 ELSE 0 END) as is_beer,
(CASE WHEN name_utf16 COLLATE Japanese_XJIS_140_CI_AS LIKE N'%🍣%' THEN 1 ELSE 0 END) as is_sushi
FROM @d
しかし、この方法は性能面では期待できない上、根本的な解決にはなってません。
そもそも、照合順序を Japanese_XJIS_140_CI_AS に設定して作成したデータベースの方は、問題なく意図した結果が得られています。
結論
SQLServerでサロゲートペアや結合文字列を扱う場合、データベース作成時に適切な照合順序を指定しましょう。
....
前述した公式サイトには、注意書きとして「SQL Server 2014 (12.x) 以降では、すべての新しい _140 照合順序で補助文字が自動的にサポートされます。」とあります。
ちなみに日本語の照合順序で指定可能な _140 系の一覧は次のクエリで取得できます。
SELECT * FROM fn_helpcollations() WHERE name LIKE 'Ja%' AND name LIKE '%_140%';
不要なトラブルを避ける意味でも、照合順序は指定するべきかと。
